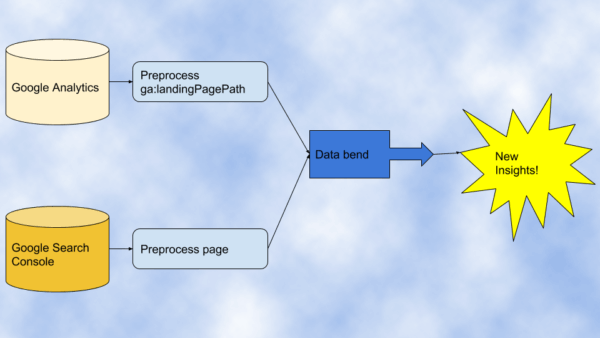
Once you preprocess columns to consistent formatting, additional data blending options include prioritizing pages with search clicks, mining internal site search for content gaps, analyzing traffic issues with 404 pages and more.
As I covered in my
previous article, data blending can uncover really powerful insights that you would not be able to see otherwise.
When you start shifting your SEO work to be more data-driven, you will naturally look at all the data sources in your hands and might find it challenging to come up with new data blending ideas. Here is a simple shortcut that I often use: I don’t start with the data sources I have (bottoms up), but with the questions I need to answer and then I compile the data I need (top-bottom).
In this article, we will explore 5 additional SEO questions that we can answer with data blending, but before we dive in, I want to address some of the challenges you will face when putting this technique to practice.
Tony McCreath raised a very important frustration you can experience when data blending:
When you join separate datasets, the common columns need to be formatted in the same way for this technique to work. However, this is hardly the case. You often need to preprocess the columns ahead of the join operation.
It is relatively easy to perform advanced data joins in Tableau, Power BI and similar business intelligence tools, but when you need to preprocess the columns is where learning a little bit of Python pays off.
 Here are some of the most common preprocessing issues you will often see and how you can address them in Python.
Here are some of the most common preprocessing issues you will often see and how you can address them in Python.
URLs
Absolute or relative. You will often find absolute and relative URLs. For example, Google Analytics URLs are relative, while URLs from SEO spider crawls are absolute. You can convert both to relative or absolute.
Here is how to convert relative URLs to absolute:
| #convert relative URLs to absolute |
| from urllib.parse import urljoin |
| #relative 404 URLs from Search Console API: webmasters.urlcrawlerrorssamples.list |
| pageUrl = “product/mad-for-plaid-flannel-dress” #missing forward slash |
| print(urljoin(“https://www.example.com/”, pageUrl)) |
| #Output -> https://www.example.com/product/mad-for-plaid-flannel-dress |
| #relative links from Google Analytics API: ga:landingPagePath |
| landingPagePath = “/about-chc/clinicians/audiology-technology/” #including forward slash |
| print(urljoin(“https://www.example.com/”, landingPagePath)) |
| #Output -> https://www.example.com/about-chc/clinicians/audiology-technology/ |
Here is how to convert absolute URLs to relative:
| #convert absolute URLs to relative |
| from urllib.parse import urlsplit, urlunsplit |
| #Absolute source URLs linking to 404s from Search Console API: webmasters.urlcrawlerrorssamples.list |
| “http://www.example.com/brand/swirly/shopby?sizecode=99”, |
| “https://www.example.com/brand/swirly” |
| #first break url into parts |
| u = urlsplit(linkedFromUrls[0]) |
| # u -> SplitResult(scheme=’http’, netloc=’www.example.com’, path=’/brand/swirly/shopby’, query=’sizecode=99′, fragment=”) |
| #then rebuild it back with empty scheme, netloc and fragment |
| relative_url = urlunsplit((“”, “”, o.path, o.query, “”)) |
| #Output -> /brand/swirly/shopby?sizecode=99 |
Case sensitivity. Most URLs are case sensitive, but If the site is hosted on a Windows Server, you will often find URLs with different capitalization that return the same content. You can convert both to lowercase or upper case.
Here is how to convert them to lowercase:
| #convert URL to lowercase |
| crawled_url = “https://www.example.com/ABOUT-chc/clinicians/audiology-technology/” |
| print(crawled_url.lower()) |
| #Output -> https://www.example.com/about-chc/clinicians/audiology-technology/ |
Here is how to convert them to uppercase:
| #convert URL to uppercase |
| crawled_url = “https://www.example.com/ABOUT-chc/clinicians/audiology-technology/” |
| print(crawled_url.upper()) |
| #Output -> HTTPS://WWW.EXAMPLE.COM/ABOUT-CHC/CLINICIANS/AUDIOLOGY-TECHNOLOGY/ |
Encoding. Sometimes the URLs come from the URL parameter of another source URL and if they have query strings they will be URL encoded. When you extract the parameter value, the library you use might or might not do it for you.
Here is how to decode URL-encoded URLs
| url_source=“/url?sa=t&source=web&rct=j&url=https://support.google.com/webmasters/answer/35291%3Fhl%3Den&ved=2ahUKEwi42-aIwP3gAhUNON8KHf4EB-QQFjAIegQIChAB” |
| #Output -> ‘sa=t&source=web&rct=j&url=https://support.google.com/webmasters/answer/35291%3Fhl%3Den&ved=2ahUKEwi42-aIwP3gAhUNON8KHf4EB-QQFjAIegQIChAB’ |
| #note the parameter ‘url’ is URL encoded because it includes a query string |
| url_params = parse_qs(u.query) |
| #Output -> [‘https://support.google.com/webmasters/answer/35291?hl=en’] |
| #in case the URL is already encoded |
| encoded_url=‘https://support.google.com/webmasters/answer/35291%3Fhl%3Den’ |
| print(unquote(encoded_url)) |
| #Output -> ‘https://support.google.com/webmasters/answer/35291?hl=en’ |
Parameter handling. If the URLs have more than one URL parameter, you can face some of these issues:
- You might have parameters with no values.
- You might have redundant/unnecessary parameters.
- You might have parameters ordered differently
Here is how we can address each one of these issues.
| from urllib.parse import urlsplit, urlunsplit |
| def clean_url_params(url): |
| #example output -> ‘sizecode=99&sort=’ |
| url_params = parse_qsl(u.query) |
| #example output -> [(‘sizecode’, ’99’)] |
| #next let’s sort the parameters so they are always in the same order |
| url_params.sort(key=lambda tup: tup[0]) # sorts in place by parameter name |
| #now we need to rebuild the URL |
| new_query = urlencode(url_params) |
| #example output -> ‘sizecode=99’ |
| new_url = urlunsplit((u.scheme, u.netloc, u.path, new_query, “”)) |
| #example output -> ‘http://www.example.com/brand/swirly/shopby?sizecode=99’ |
| #Absolute source URLs linking to 404s from Search Console API: webmasters.urlcrawlerrorssamples.list |
| “http://www.example.com/brand/swirly/shopby?sizecode=99&sort=”, |
| “https://www.example.com/brand/swirly?sort=asc&sizecode=99”, |
| “https://www.example.com/brand/swirly?sizecode=99&sort=asc”, |
| #You might have parameters with no values. For example, sort= |
| clean_url_params(linkedFromUrls[0]) |
| #Output: http://www.example.com/brand/swirly/shopby?sizecode=99&sort= -> http://www.example.com/brand/swirly/shopby?sizecode=99 |
| #You might have parameters ordered differently |
| clean_url_params(linkedFromUrls[1]) |
| clean_url_params(linkedFromUrls[2]) |
| # https://www.example.com/brand/swirly?sort=asc&sizecode=99 -> https://www.example.com/brand/swirly?sizecode=99&sort=asc |
| # https://www.example.com/brand/swirly?sizecode=99&sort=asc -> https://www.example.com/brand/swirly?sizecode=99&sort=asc |
Dates
Dates can come in many different formats. The main strategy is to parse them from their source format into Python datetime objects. You can optionally manipulate the datetime objects. For example, to sort the dates correctly or to localize to a specific time zone. But, most importantly, you can easily format the datetime dates using a consistent convention.
Here are some examples:
| #Reformating date strings |
| #Crawled and first discovered dates from the Search Console API: webmasters.urlcrawlerrorssamples.list |
| last_crawled= “2019-01-12T04:00:59.000Z” #ISO-8601 date |
| first_detected= “2018-11-19T02:59:25.000Z” |
| from datetime import datetime |
| #Here is how to parse dates the hard way. See https://docs.python.org/3/library/datetime.html#strftime-and-strptime-behavior |
| dt = datetime.strptime(last_crawled, ‘%Y-%m-%dT%H:%M:%S.%fZ’) #you need to create a precise date format string |
| #output -> datetime.datetime(2019, 1, 12, 4, 0, 59) |
| #Here is how to do this the easy way using https://pypi.org/project/python-dateutil/ |
| dt = dateutil.parser.parse(last_crawled) |
| #output -> datetime.datetime(2019, 1, 12, 4, 0, 59, tzinfo=tzlocal()) |
| #Google Analytics API ga:date |
| dt = dateutil.parser.parse(ga_date) |
| #output -> datetime.datetime(2019, 3, 11, 0, 0) |
| #Latest links crawled date |
| Last_crawled= “Mar 4, 2019” |
| dt = dateutil.parser.parse(Last_crawled) |
| #output -> datetime.datetime(2019, 3, 4, 0, 0) |
| #finally we can format any these datetime objects using a consistent format |
Keywords
Correctly matching keywords across different datasets can also be a challenge. You need to review the columns to see if the keywords appear as users would type them or there has been any normalization.
For example, is not uncommon for users to search by copying and pasting text. This type of keyword searches would include hyphens, quotes, trademark symbols, etc. that would not normally appear when typed. But, when typing, spacing and capitalization might be inconsistent across users.
In order to normalize keywords, you need to at least remove any unnecessary characters and symbols, remove extra spacing and standardize in lower case (or upper case).
Here is how you would do that in Python:
| from urllib.parse import unquote_plus |
| #standardize keyword by removing extra characters, space, url decoding and lowercase capitalization |
| def normalize_keywords(keyword): |
| bad_chars=“\’\”®” #add more as needed |
| table = str.maketrans(dict.fromkeys(bad_chars)) |
| keyword = unquote_plus(keyword) |
| keyword = keyword.lower() |
| keyword = re.sub(‘[\s]+’, ‘ ‘, keyword) |
| keyword = keyword.translate(table) |
| #Check the dimensions and metrics explorer https://developers.google.com/analytics/devguides/reporting/core/dimsmets |
| #ga:keyword -> utm_term tracking parameter (manual campaign tracking) with quotes |
| ga_keyword = “‘solo female traveling\”“ |
| normalize_keywords(ga_keyword) |
| #Returns -> ‘solo female traveling’ |
| #ga:searchKeyword -> Internal Search Term with special symbol |
| ga_search_keyword = “10 days in Disneyland®” |
| normalize_keywords(ga_search_keyword) |
| #Returns -> ’10 days in disneyland’ |
| #ga:searchKeywordRefinement -> Subsequent internal search term with capitalized words and extra white space |
| ga_search_keyword_refinement = “10 day music cities NASHVILLE to NEW ORLEANS” |
| normalize_keywords(ga_search_keyword_refinement) |
| #Returns -> ’10 day music cities nashville to new orleans’ |
| #ga:adMatchedQuery -> Search query that triggered impressions -> normalized |
| ga_ad_matched_query = “travel for single women” |
| normalize_keywords(ga_ad_matched_query) |
| #Returns -> ‘travel for single women’ |
| #search_url -> Google Search -> copy and pasted text, URL encoded |
| from_search_url = “DA+doesn’t+influence+your+Google+rankings” |
| normalize_keywords(from_search_url) |
| #Returns -> ‘da doesn’t influence your google rankings’ |
Now that we know how to preprocess columns, let get to the fun part of the article. Let’s review some additional SEO data blending examples:
Error pages with search clicks
You have a massive list of 404 errors that you pulled from your web server logs because Google Search Console doesn’t make it easy to get the full list. Now you need to redirect most of them to recover traffic lost. One approach you could use is to prioritize the pages with search clicks, starting with the most popular ones!
Here is the data you’ll need:
Google Search Console: page, clicks
Web server log: HTTP request, status code = 404
Common columns (for the merge function): left_on: page, right_on: HTTP request.
Pages missing Google Analytics tracking code
Some sites choose to insert tracking codes manually instead of placing them on web page templates. This can lead to traffic underreporting issues due to pages missing tracking codes. You could crawl the site to find such pages, but what if the pages are not linked from within the site? One approach you could use is to compare the pages in Google Analytics and Google Search Console during the same time period. Any pages in the GSC dataset but missing in the GA set can potentially be missing the GA tracking script.
Here is the data you’ll need:
Google Search Console: date, page
Google Analytics: ga:date, ga:landingPagePath, filtered to Google organic searches.
Common columns (for the merge function): left_on: page, right_on: ga:landingPagePath.
Excluding 404 pages from Google Analytics reports
One disadvantage of inserting tracking codes in templates is that Google Analytics page views could trigger when users end up in 404 pages. This is generally not a problem, but it can complicate your life when you are trying to analyze traffic issues and can’t tell which traffic is good and ending in actual page content and which is bad and ending in errors. One approach you could use is to compare pages in Google Analytics with pages crawled from the website that return 200 status code.
Here is the data you’ll need:
Website crawl: URL, status code = 200
Google Analytics: ga:landingPagePath
Common columns (for the merge function): left_on: URL, right_on: ga:landingPagePath
Mining internal site search for content gaps
Let’s say that you review your internal site search reports in Google Analytics and find people coming from organic search and yet performing one or more internal searches until they find their content. It might be the case that there are content pieces missing that could drive those visitors directly from organic search. One approach you could use is to compare your internal search keywords with the keywords from Google Search Console. The two datasets should use the same date range.
Here is the data you’ll need:
Google Analytics: ga:date, ga:searchKeyword, filtered to Google organic search.
Google Search Console: date, keyword
Common columns (for the merge function): left_on: ga:searchKeyword, right_on: keyword
Checking Google Shopping organic search performance
Google announced last month that products listed in Google Shopping feeds can now show up in organic search results. I think it would be useful to check how much traffic you get versus the regular organic listings. If you add additional tracking parameters to the URLs in your feed, you could use Google Search Console data to compare the same products appearing in regular listings vs organic shopping listings.
Here is the data you’ll need:
Google Search Console: date, page, filtered to pages with the shopping tracking parameter
Google Search Console: date, page, filtered to pages without the shopping tracking parameter
Common columns (for the merge function): left_on: page, right_on: page